Saving time in open-source
Following the trail of best practices.

Illustration of PEP 20 principles in sumi-e (Japanese brush painting) style.
In computational research, it is a standard to publish code alongside manuscripts for reproducibility. However, most of that code is not designed to be reused for other applications. Consequently, new methods are less accessible to the community, resulting in a lower impact. Thus, the question is: How to achieve long-term reusability with minimal effort? The simple answer: You can’t. - There is no easy open-source recipe. Nevertheless, we can avoid the most common pitfalls by learning from experience of others.
For this blog post, I spoke with Lukas Heumos and Adrian Šošić. Both are open-source Python developers but come from different backgrounds - academia and industry. Despite that, our discussion revealed that they face similar hurdles.
Lukas is software developer and bioinformatics scientist who contributed to numerous open-source projects. He is best known for his pioneering role in scverse - a consortium of foundational tools for analyzing single-cell data. The scverse community has developed more than 50 high-quality packages with over 50 contributors.
Adrian is data scientist and software developer with industry experience. He is a core developer of the BayBE package, designed for Bayesian optimization of chemical experiments. Originally developed at Merck KGaA Darmstadt, the package has been open-sourced and has since gained widespread popularity both within the company and in the broader community.
With Lukas and Adrian we talked about anecdotes. This is reflected in the blog post, which does not aim to present a comprehensive guide for any of the discussed topics. Also, given that all three of us primarily code in Python, many examples are Python-based. Nevertheless, the open-source principles we discussed are applicable across different programming languages.
This blog post is predominately based on discussions with Lukas and Adrian. However, for the sake of readability, I often omit their names.
Sections list
- Following the trail of best practices
- The crossroads at which you should not take the wrong path
- Code standards
- GitHub history
- Taming dependencies
- Keeping code running consistently
- Keeping code running correctly
- Good contributions are never one-sided
- From coding to community
Following the trail of best practices
If you’re looking for an easy recipe for setting up Python packages, here’s mine: First, find the latest repository from Lukas. Second, copy over all his packaging code and use it. This prompts the question: How does Lukas stay updated on current best practices?
A good starting point is to follow widely accepted standards, such as PEPs (Python Enhancement Proposals). PEPs outline Python design guidelines and new features. Although the extensive PEP index may not seem like an inviting weekend read, a closer look reveals hidden gems amid the technical specifications (Figure 1).
 Figure 1: PEP 20, also known as “The Zen of Python”. If you ever want to quickly refer to it when writing Python code, just type
Figure 1: PEP 20, also known as “The Zen of Python”. If you ever want to quickly refer to it when writing Python code, just type import this.
Besides following PEPs, useful standards can also be found within the community. In search of unwritten upcoming practices, Lukas regularly flips through GitHub pages of bigger tech companies and open-source initiatives. He also follows developers’ posts and Reddit communities1 (Figure 2).
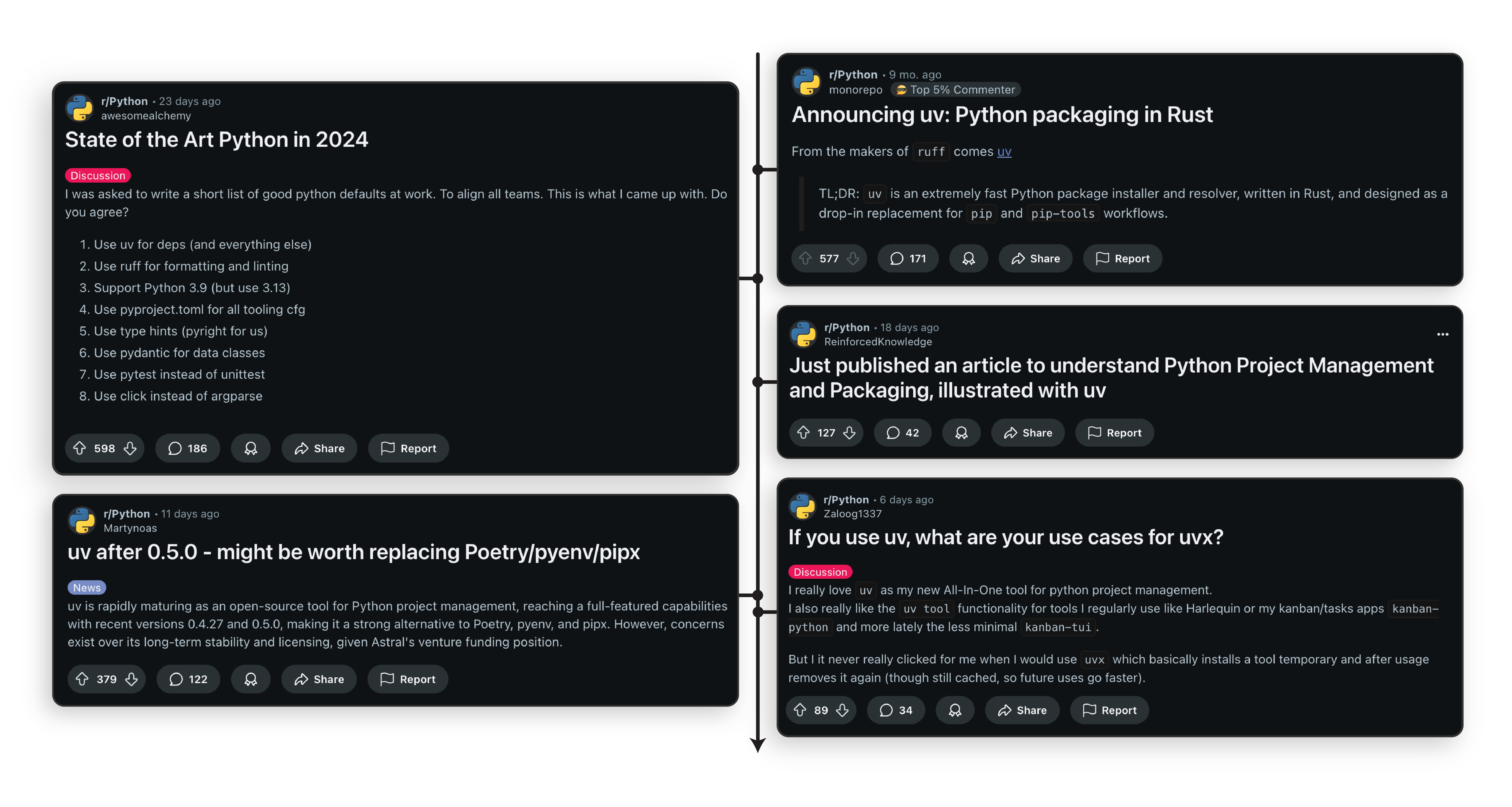 Figure 2: Emerging best practices can be discovered from community discussions. This example shows how
Figure 2: Emerging best practices can be discovered from community discussions. This example shows how uv gained popularity among Python developers on Reddit. The figure is composed of screenshots taken on 24. 11. 2024. Some of the posts were cut for brevity.
Last but not least, exchange with colleagues should not be overlooked. Although I had previously worked with both Adrian and Lukas, I was surprised by how many new insights came up during the interview.
Drawing from all these sources, a picture of evolving coding practices can be formed. The next step is to determine what works - and what doesn’t - for your specific package.
The crossroads at which you should not take the wrong path
In conversations with Adrian and Lukas, a topic that surfaced over and over again was the limited time available to developers - the main constraint on their projects. However, both underlined that time-saving should never be short-term. Code changes should be made with a long-term focus, aiming to streamline future package development. Or as PEP20 aptly states: “Never is often better than right now.”
Below I summarize why establishing contribution standards was crucial for their long-term project success. These standards encompass not only code style but also how GitHub is used to manage version history and the efforts to keep the package user-friendly throughout its lifecycle.
Code standards
Python comes with its own coding style. Nevertheless, each of us has a personal opinion on how things should be implemented. While discussions about code are valuable, there are times when they do not bring much. In such cases, sheepishly following predefined standards is genuinely the best thing to do (Figure 3).
 Figure 3: Following existing standards rather than re-inventing new ones can save a lot of time for coding.
Figure 3: Following existing standards rather than re-inventing new ones can save a lot of time for coding.
A clear standard can be set by using automated pre-commit formatting tools, called linters. Besides saving developers’ time from unfruitful discussions, they also ensures that no poorly formatted code can be pushed to GitHub.
GitHub history
For many of us git commit is not much more than a line required before sharing code with git push. However, Adrian emphasized that we need to reconsider this, beginning with the underlying question: Why do we even track history?
History helps us find and resolve errors that crept into our past code (Figure 4). However, if our commits and pull requests are not compact and self-contained or if associated notes are not informative, the history will not help us pinpoint the bugs.
Example
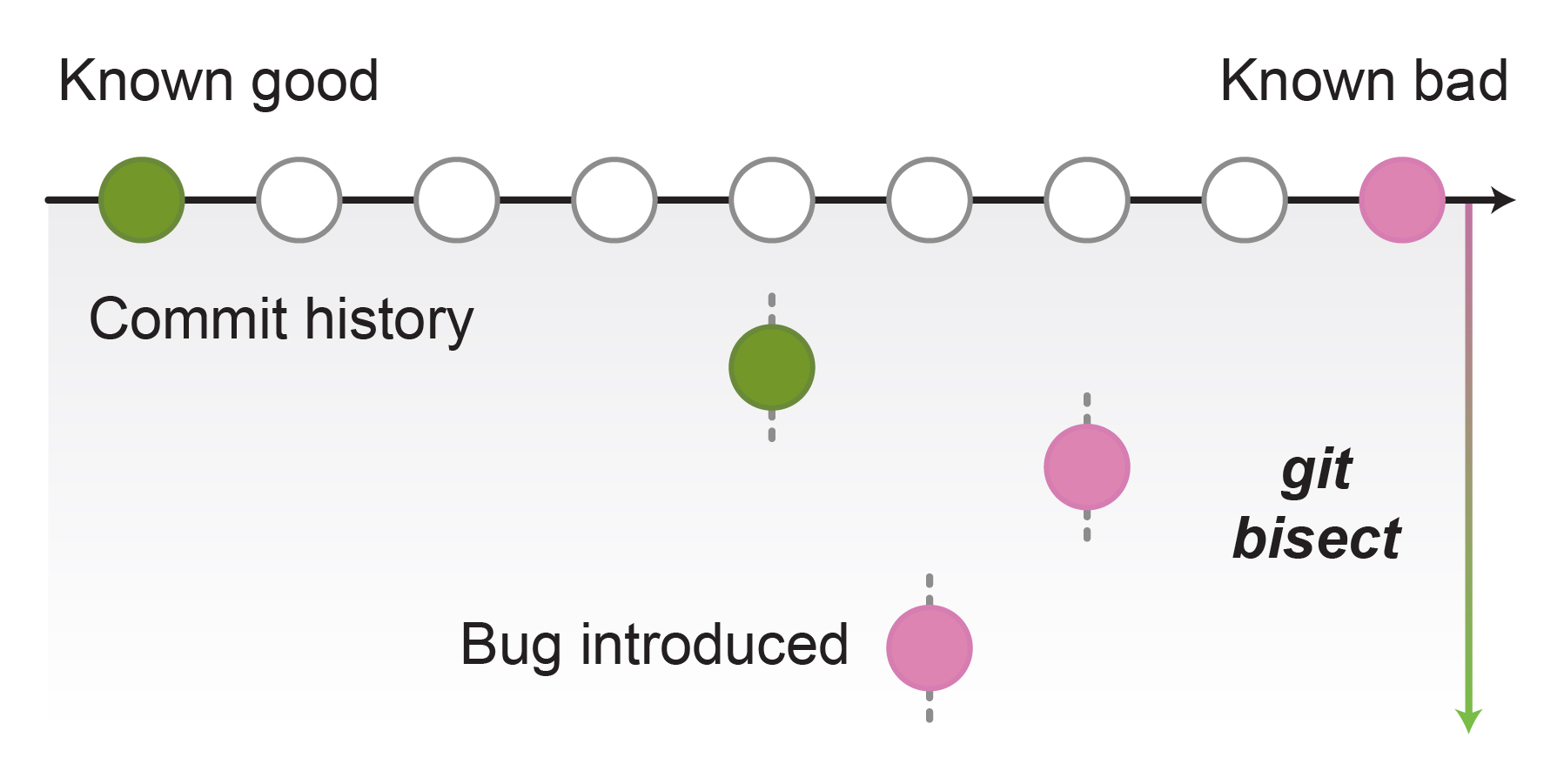 Figure 4:
Figure 4: git bisect helps to pinpoint the commit that introduced a bug. This is achieved with a binary search between known bug-free and bug-containing commits.
To effectively manage code modifications, three rules are of special importance:
- Individual pull requests and commits should be as concise as possible. Ideally, one pull request should address no more than one bug or one new feature.
- While
diffreveals how the code has changed, our descriptions should concisely convey which functionality has been modified and why the change was necessary (Figure 5). - Commits should be easily searchable. Thus, they must be free of spelling mistakes and all contributors should follow consistent naming conventions.
 Figure 5: Best practices for commit messages.
Figure 5: Best practices for commit messages.
Opinions on how to manage history, however, diverge. One approach is to squash all commit messages from a single pull request into a single commit. The change is then explained in the pull request body, which has additional value due to the accompanying discussions. While commit squashing results in a more condensed history, focusing on individual commits offers greater granularity. This is required especially when pull requests get out of hand, becoming large and unwieldy.
A note on discarding history
git bisect, but also the authorship information will be lost, preventing us from reaching out to the original code-block author for clarification.Taming dependencies
Managing dependencies was flagged as a hurdle by both Adrian and Lukas. When developing a package, it’s crucial to consider how easily users will be able to integrate it into their own code. This differs from writing other types of code, such as for individual analyses or self-contained applications. In these, dependencies can be simply pinned, bypassing many of the considerations necessary for creating a lean package.
There are multiple arguments for keeping the dependency list lean:
- A package must be installable on different operating systems and alongside many other packages. Dependencies that are incompatible with any of those will impede the package use.
- A large number of dependencies increases both installation time and package size. This poses challenges not only for end users but also for continuous integration tests run automatically through GitHub Actions. Each test creates a new virtual machine, which requires installing all dependencies from scratch, slowing down the testing.
- Certain dependencies can significantly increase import or runtime, leading to a poor user experience and slower development progress. For contributors, longer wait times, such as five minutes for unit tests instead of one, reduce the number of code iterations that can be completed within a limited time frame.
- A large number of dependencies makes a package harder to maintain over time. This includes dealing with incompatibilities among dependencies and handling changes in the programming interfaces of the used dependencies.
Multiple strategies to mitigate the above challenges exist:
- Packages may be added as optional dependency groups for specific operating systems or niche functionalities2.
- Dependencies may be carefully selected based on their speed, size, or compatibility. For example,
Ruffcan be used for faster linting,uvfor packaging, andmatplotlibinstead ofplotlydue to lower secondary dependency weight. - Widely-adopted packages are preferred due to stability. Furthermore, it is likely that users will already have them pre-installed.
- If only a minute part of an external package is required, it may be worth re-implementing the functionality rather than using the package as a dependency.
- Long import times can be solved by lazy loading to delay the loading of a package until it is actually needed, avoiding unnecessary imports. However, to make lazy loading truly efficient, changes in package architecture may be needed.
Example on lazy-loading
torch.Tensor objects, broadly requiring PyTorch imports. Thus, they re-designed the data storage with numpy and pandas, retaining PyTorch imports only where it was strictly needed for computation. For many use cases, this has importantly sped up package loading.When it is unclear where dependency bottlenecks are, profiling tools such as tuna or scalene can be used to monitor runtime or compute and memory consumption, respectively. Similarly, GitHub actions can be used to test if the package can be run with different Python versions or on different operating systems and to assess the corresponding performance. For example, PyTorch installation requires much less storage space on macOS than Linux due to Linux-specific CUDA dependency.
Keeping code running consistently
Sound initial design choices are key for future developments. They will affect the ease of adding new features and are essential for maintaining a consistent programming interface for users, ensuring backward compatibility.
The code consistency topic represents, in Adrian’s opinion, the most substantial set of challenges for package development. He warned of the lock-in effect, where poorly designed code hinders future modifications, locking one into suboptimal design choices.
Example
Benchmark class may not be the best place to store this information. In the future, one may also want to perform benchmarks on combinations of multiple datasets. This naturally calls for a Dataset class, which stores all relevant dataset attributes, including the maximal performance for that dataset. Multiple datasets with different properties can then be added to a benchmark. However, we started with a Benchmark class interface containing a parameter for a maximal performance value. This parameter can not be simply removed, as this would break the code of users relying on it. Now, we are stuck with a “dead” parameter that will remain unused in new use cases.Thus, Adrian suggested that class responsibilities must be carefully crafted with their long-term consequences in mind. While this may extend the initial development process, it will ease future developments. Or to put it simply: “One needs to have sufficient confidence in all changes integrated into the main branch to consistently impose their use in the future.“
In addition, one can follow code patterns that increase future flexibility. For example, the amount of user-exposed code can be limited to ease the refactoring of private code.
However, in some cases, it is not possible to overcome past mistakes entirely. Therefore, a deprecation mechanism should be implemented to warn users about upcoming changes before they occur.
Besides code consistency, documentation consistency is likewise important. Documentations should be versioned to match individual code releases. This will guard against users running into errors when using features not yet available or deprecated in their installed package version.
Keeping code running correctly
Some may argue that good documentation is sufficient for using a package correctly. However, I am leaning toward the side advocating for actively anticipating and preventing possible user errors. As a user, I’ve often found myself spending heaps of time trying to decipher a low-level bug, only to realize that I had accidentally passed a string instead of a collection of strings to a function. Or as Douglas Adams would put it: “A common mistake that people make when trying to design something completely foolproof is to underestimate the ingenuity of complete fools.”
To prevent the above-mentioned user error, one could employ the attrs or pydantic packages. They enhance class initialization, including type checking and automatic type conversions.
Another common user mistake is overlooking that an object will be modified within a certain use case. For example, we may pass a Dataset object to a plotting function to create a graph. However, if the function modifies the Dataset object in place, this would be a rather unexpected behavior from the user’s perspective. It may lead to downstream errors when the same Dataset object is re-used. Thus, avoiding such contra-intuitive design patterns, even if documented, would be preferable.
However, clever code design is not enough. Reliable tests are an indispensable part of any package. - If there are bugs, people will sooner or later run into them. While there are many ways to design tests, a recently popularised package is hypothesis. It identifies edge-case errors, such as passing zero or infinite float values. This is achieved by automatically generating test cases with diverse inputs (Figure 6). Afterward, hypothesis aids in debugging by pinpointing the simplest input scenario that results in an error.
 Figure 6: Hypothesis helps to identify hidden bugs by expanding test parametrization. Some parameter values may be overlooked by a programmer (left) but not by Hypothesis (right). This is a mock example representing the key aim of Hypothesis and not a real code snippet. For using Hypothesis please refer to the official documentation.
Figure 6: Hypothesis helps to identify hidden bugs by expanding test parametrization. Some parameter values may be overlooked by a programmer (left) but not by Hypothesis (right). This is a mock example representing the key aim of Hypothesis and not a real code snippet. For using Hypothesis please refer to the official documentation.
Besides unit tests, which test individual functionalities and should be run upon making any code modifications, there are also integration tests. These assess whether individual features correctly integrate together by executing large-scale workflows or even full tutorials3. Furthermore, they can be used to track unexpected output changes, such as degraded model performance.
Lastly, when talking about package errors in a broader sense, it is also important to consider how the outputs of the package are presented in different code interfaces. For example, Lukas described his past attempt to increase the readability of terminal outputs by color-coding different message types. However, this backfired as the palette was not compatible with custom terminal styles employed by some users. For example, a red error message may not be visible on a terminal with a red background. To overcome the font color issue, Lukas decided to start his messages with emoji Unicodes that get consistently rendered into emojis on the user side (Figure 7).
 Figure 7: Terminal messages with emojis for improved readability. Taken from Lamin’s tutorial on
Figure 7: Terminal messages with emojis for improved readability. Taken from Lamin’s tutorial on DataFrame curation.
Good contributions are never one-sided
One of the responsibilities of any core developer is managing contributions from others. It’s crucial to strike a balance between maintaining high code standards and keeping contributors motivated. Adrian and Lukas offered several suggestions for achieving this balance:
- Be firm but kind.
- Avoid being too picky. Specify which changes are a must and which are less important.
- Provide code suggestions to help newcomers learn and demonstrate that you are ready to offer support.
- Format the requested changes as a step-wise guide with sufficient details as well as implementation suggestions.
- In some cases, it may be easiest to discuss in person rather than creating lengthy conversation threads. However, this comes with the drawback of losing unwritten information, which could otherwise serve as a valuable resource for others encountering similar issues.
A note on LLM review tools
In a former section, I discussed the importance of keeping pull requests short from the perspective of modification history. However, this also makes the review process more manageable:
- It will help to converge on a solution, easing the review process for all parties.
- Quicker review times will reduce the likelihood of branch desynchronization, simplifying the final merge back into the
mainbranch.
In addition to a supporting review process, it’s essential to design a clear and helpful contributor guide. Without one, initial pull requests may strongly deviate from the package’s core principles, potentially making them unusable. There are several ways in which a contributor guide can be improved:
- Striking the right balance between brevity and accessibility can be challenging when considering contributors with diverse backgrounds. Referring to external guides, such as how to use GitHub, can help to reduce the length and keep the information on external resources up to date.
- A high-level class diagram can clarify the general package architecture for newcomers. This not only speeds up initial contributions but may also lead to better design choices.
- Rather than providing a lengthy description of code standards, it’s better to use automated tools, such as linters, to check for potential errors and standard violations.
- Publishing a roadmap of planned changes safeguards against contributors basing their enhancements on features that will be altered in the near future.
From coding to community
When Lukas was asked about his favorite open-source project, his answer was clear: scverse. He enjoyed the recognition of their efforts and valued being part of the community. The project allowed him to gain a diverse set of skills and to benefit from the knowledge shared by other collaborators.
Organizing larger open-source initiatives involves responsibilities beyond coding, such as managing people. While code contributions can come from anywhere in the world, both Lukas and Adrian highlighted that working across different organizations and locations presents additional challenges. It can limit exchange and even create disconnected local hubs.
As a manager of an open-source initiative, it is key to pave the way for information flow. The first step is coordinating shared meeting times. Additionally, the value of in-person meetings should not be underestimated. Lukas emphasized that the scverse conference was not only appreciated by the wider community but also boosted the motivation of the core developers.
Besides immediate community management, it is also important to plan for the future. Regular discussions about career progression and realistic time commitments are key. Without them, new members may not be ready to step up when experienced veterans move on.
While this section provided some glimpses into managing open-source communities, the topic is far too broad to be fully covered in this post. Even so, it should never be overlooked when planning long-lasting open-source projects.
Key takeaways
While most of us code alone, we must keep in mind that open-source packages are inextricably intertwined with the community. Thus, spending more time on decisions rather than new lines of code is a habit that one needs to get into.
Footnotes
When we spoke in November of 2024, Lukas suggested r/programming and r/Python as well as r/ExperiencedDevs for more career-oriented discussions. However, he noted that communities change through time, prompting one to find new ones. He also recommended the blogs of Will McGugan, the main developer of Rich package for formatting terminal outputs, Tushar Sadhwani, and Charlie Marsh, a developer of Ruff linting package. ↩︎
There is no way to specify opt-out dependencies that would be installed by default except if actively opted out. For example, this would be beneficial for user-statistics telemetry, where it is desired to increase the number of users prepared to share their data. ↩︎
Integration tests often have extended runtimes. This can be mitigated with smaller input datasets. To enable a reliable assessment of output quality, one must find a good balance between a smaller dataset size and the naturalness of the data properties. Moreover, integration tests can be sped up by buying faster runners for GitHub actions. ↩︎