Model interactions for interactive segmentation
Building models through a magnifying glass.

How are great models made? Often, by getting hands dirty in the methodological muck.
For this blog post, we discussed what it takes to design practically-applicable interactive segmentation models with Maximilian Rokuss, Fabian Isensee, Hallee E. Wong, and Anwesa Choudhuri. Their main piece of advice was: carefully choose individual methodological components that make up the full framework.
Summary of the discussed papers
Hallee developed ScribblePrompt (Wong, 2024a), an interactive segmentation method for 2D medical images. Max and Fabian are authors of nnInteractive (Isensee, Rokuss, and Krämer, 2025), an interactive segmentation method for 3D medical images. Both works focused on providing a robust and user-centric tool.
Anwesa contributed to the order-aware interactive segmentation method (Wang, 2025). This model has an improved capacity for distinguishing between objects as it incorporates object-centric and depth-related information.
This blog post highlights topics that got less focus in the papers. If you are more generally interested in interactive segmentation, I recommend reading the original papers, as many topics are skipped here. Furthermore, this post does not aim to provide a comprehensive overview of the field and instead focuses on anecdotes from our conversations.
While this blog post is based on discussions with Max, Fabian, Hallee, and Anwesa, I often omit their names for the sake of readability.
Sections list
- Brief introduction of interactive segmentation
- Forged in the rubble
- Knowing when (not) to use SOTA
- Methods that survive in the real world are user-friendly
- Teaching the model to follow the user
- Simulating realistic interactions
- Capturing diverse user intents
- Not all interactions are equally valuable
- Designing models that can run in practice
- Data loading for swifter training
- Carefully planned data curation
- Data diversity for model training
Brief introduction of interactive segmentation
The aim of interactive segmentation is to generate an object mask given consecutive user prompts. By providing a series of prompts, such as scribbles or bounding boxes marking foreground and background regions, users can guide the model to iteratively refine its prediction (Figure 1).
The models are trained on images with corresponding object masks, for which user prompts are synthetically generated (Figure 1). After placing initial prompts, the first mask is generated. Subsequent prompts are iteratively simulated in regions of disagreement between the ground-truth and predicted mask until a stopping criterion is met.
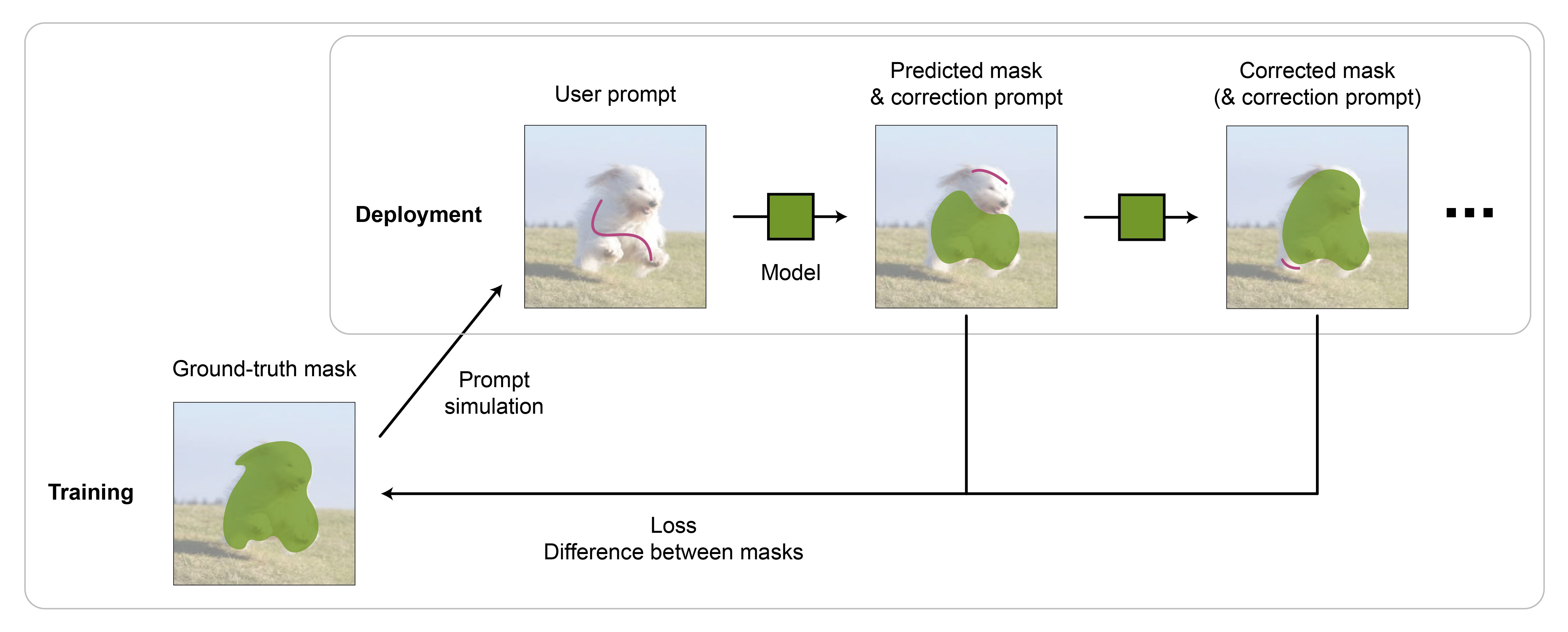 Figure 1: Overview of the interactive segmentation task and the model training procedure.
Figure 1: Overview of the interactive segmentation task and the model training procedure.
Forged in the rubble
A topic that surfaced in all discussions was the importance of understanding where existing, as well as your own, methods fail and crumble. To get a feel for these weak spots, everyone took on the role of the user, pinpointing improvements necessary for making the method useful in real-world scenarios.
Building a user interface for yourself
To provide an overview of the field, most papers include tables comparing the strengths and weaknesses of existing approaches. In most cases, these tables are designed in the paper writing phase, primarily to persuade readers to adopt the newly developed method. However, Max and Fabian pointed out that gaining a broader overview of the methodological landscape should not be delayed till the very end. - By understanding where the current literature falls flat, they were able to devise a focused improvement plan and subsequently develop their method in just a few months1. In the same vein, Anwesa shared that her most important project-management takeaway was the importance of understanding where baselines fail, before diving into developing new solutions.
Recognizing these limitations naturally opens paths for improvement. The nnInteractive and the ScribblePrompt papers contain a myriad of design tricks, each contributing towards a robust method. - Or as Fabian would put it: “magic”. While many of them are not self-explanatory at first, they all reflect the authors’ dedication to discovering potential pitfalls and thoughtfully crafting solutions.
The authors behind the three papers presented distinct strategies for optimizing their methods:
- At first, it is useful to explore which approaches contributed to the success of past works. For example, Max and Fabian provided multiple examples of how the inspiration from prior work and the use of existing infrastructure contributed to the project2.
- Everyone agreed that visual exploration across all stages of method development helps to pinpoint promising modelling strategies. Such exploration was essential, as comprehensively testing diverse modeling approaches would have required excessive computational resources.
- When systematic benchmarks are performed, they can be streamlined with experiment management tools (e.g., Hydra, SEML, or Pylot - the latter suggested by Hallee; Figure 2).
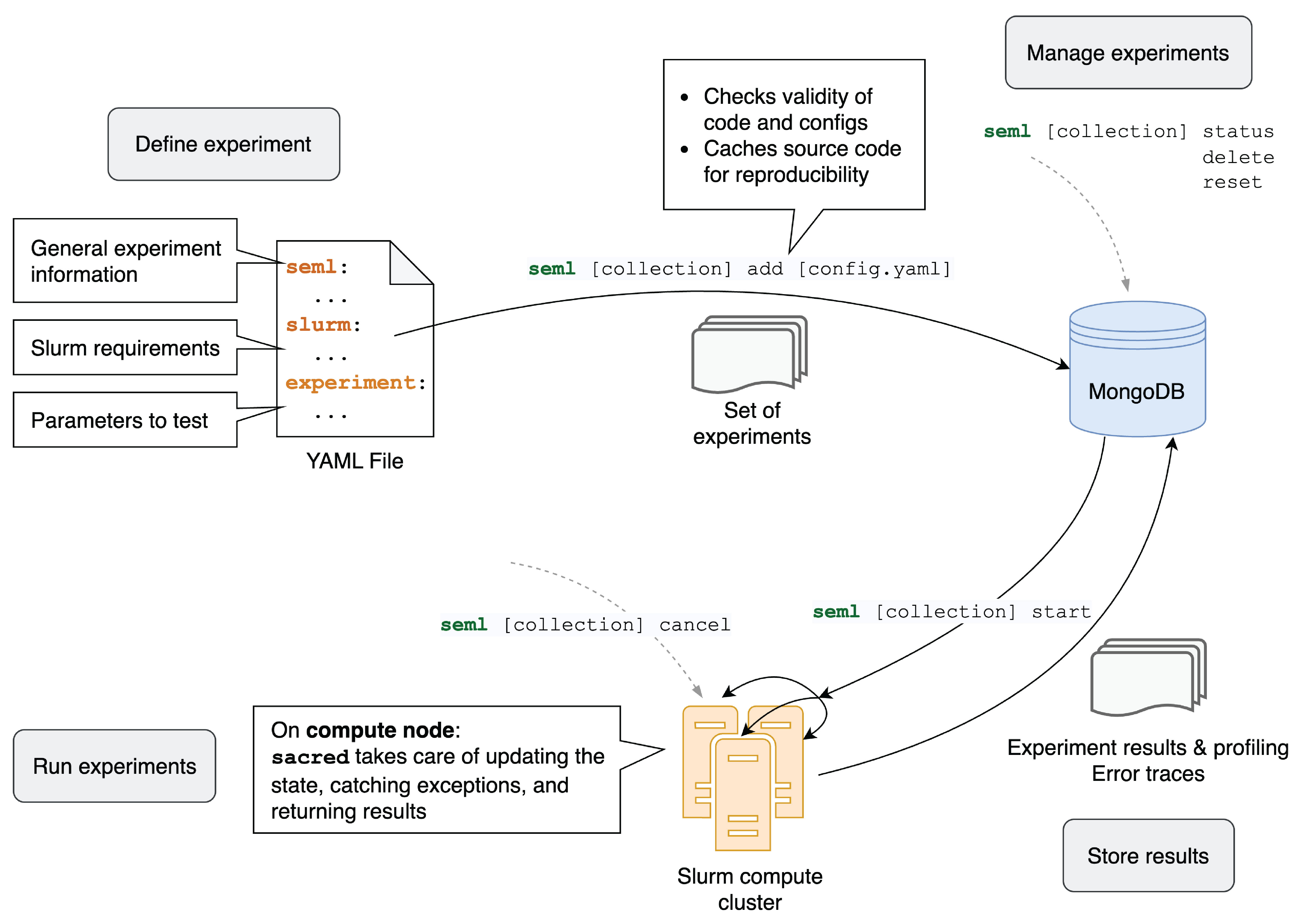 Figure 2: Overview of the Seml experiment management tool. Seml automates parameter searches, job submission to Slurm, resource profiling, and tracking of results corresponding to individual configurations. The image was adapted from Seml’s documentation, which is under the MIT license.
Figure 2: Overview of the Seml experiment management tool. Seml automates parameter searches, job submission to Slurm, resource profiling, and tracking of results corresponding to individual configurations. The image was adapted from Seml’s documentation, which is under the MIT license.
Lack of recognition for thoughtful engineering
Knowing when (not) to use SOTA
Breakthrough methods, such as SAM3 (Kirillov, Mintun, Ravi, and Mao, 2023), usually inspire a wave of new developments. However, the trick is in knowing when these methods are actually useful for the task at hand and when they are not the right fit.
Fabian presented an example: SAM’s impressive performance largely stems from having a good understanding of natural image objects due to its extensive pre-training. This allows SAM to extract meaningful information from natural images and produce high-quality embeddings (Figure 3a). But when the same approach is applied to medical imaging, either through re-training or fine-tuning, the advantage from pre-training diminishes significantly. Thus, in medical imaging contexts, architectures that perform well when trained from scratch, such as convolutional networks (Isensee, Wald, Ulrich, and Baumgartner, 2024), can be preferred. Often, they surpass architectures that achieved state-of-the-art performance on natural images, as evidenced by ScribblePrompt and nnInteractive.
Moreover, SAM relies on good pre-trained image representation for late fusion between extracted image features and user prompts (Figure 3a). Thus, user prompts can attend to compressed image features instead of the full image, improving efficiency. However, late fusion performs worse when applied to out-of-distribution images that are not well understood by the encoder. Namely, if the encoder is unable to extract high-quality image features, subsequent prompt integration will also be unsuccessful. This challenge applies to medical imaging, where a general-purpose, high-quality feature extraction model is absent. To overcome this, ScribblePrompt and nnInteractive adopted early fusion, allowing user inputs to directly influence feature extraction from images (Figure 3b).
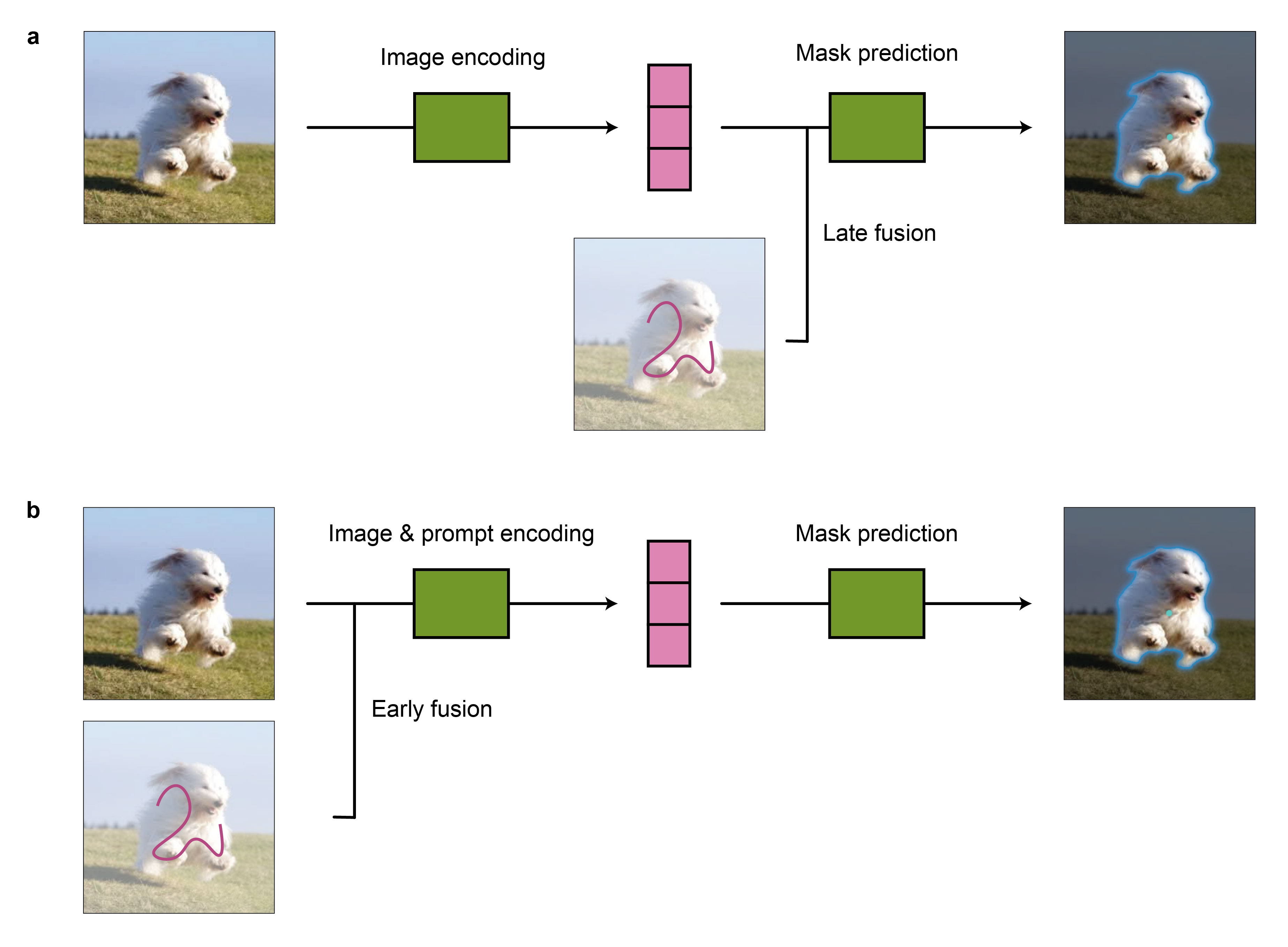 Figure 3: Extraction and merging of image and prompt features. (a) Pre-trained image encoders can be used to extract high-quality image features that can be subsequently merged with prompt information for mask prediction (late fusion). (b) Prompt and image information can be combined early on to improve the extraction of relevant features for mask prediction (early fusion). The example mask was created with SAM’s demo interface.
Figure 3: Extraction and merging of image and prompt features. (a) Pre-trained image encoders can be used to extract high-quality image features that can be subsequently merged with prompt information for mask prediction (late fusion). (b) Prompt and image information can be combined early on to improve the extraction of relevant features for mask prediction (early fusion). The example mask was created with SAM’s demo interface.
Hallee also emphasized prior research indicating that medical data typically has lower complexity than natural images and can be modeled with smaller architectures (Raghu and Zhang, 2019). Consequently, large architectures are unfavourable as they increase computational costs without substantial performance gains. Indeed, when she applied the same training technique on a fully-convolutional U-Net and the SAM architecture, the U-Net had lower latency and similar or even better segmentation performance4.
That said, pre-trained natural image models can nevertheless be valuable in the medical imaging field. For example, among the different methods for creating synthetic training masks, Max observed that SAM2 performed the best.
Pre-trained models for complementary information
Pre-trained models, designed to extract specific types of features, can provide valuable complementary information. This forms the basis of the order-aware segmentation paper, which utilizes existing models for predicting image depth. Based on this, the model can segment visually intertwined background and foreground objects, such as a bike tire positioned in front of a metal pole.
Anwesa also speculated that other model types might implicitly possess depth information. For instance, video segmentation models could gain depth-awareness through temporal occlusion dynamics.
Additionally, she emphasized that the object-understanding capabilities of current pre-trained natural image models require improvement to further enhance segmentation performance.Methods that survive in the real world are user-friendly
To make a practically useful method, it must be designed with the intended use cases and preferred user behaviours in mind. The best way to achieve this is by engaging directly with the users.
For example, ScribblePrompt’s user study resulted in many useful suggestions from the community, which guided Hallee in her future work (Wong, 2024b). Likewise, the nnInteractive team had a solid understanding of user needs from the beginning, which helped to streamline their development process.
The first two user-centric questions that must be answered are:
- What type of data do they want to analyse?
- How do they prefer to interact with the tool?
Types of data users may want to analyse
- generated with diverse imaging techniques,
- 2D or 3D,
- varying in resolution as well as 3D voxel spacing,
- displaying different biological structures, with individual components being of varying significance for each user (e.g., an organ or a tumor region).
As interactive segmentation methods rely on user input for segmentation, it is essential to consider which input types are most convenient for users. For example, the nnInteractive team realized that 3D prompting (e.g., via 3D bounding boxes) is very impractical on a 2D screen. Instead, they were able to show that even 2D interactions enable 3D segmentation.
Another sought-after capability is learning from past interactions with similar images, including images of individual patients captured at different time points. With this in mind, in-context learning interactive segmentation methods are being developed (Wong, 2024b; Rokuss, 2025).
Moreover, most tools focus on starting interactive segmentation from scratch, using unannotated images. However, some users already have imperfect segmentations that they want to refine, which presents a special type of prompt that nnInteractive and ScribblePrompt already support.
In the future, interactive segmentation methods could also be adapted for completely different workflows. For example, while routine radiology reports and doctor dictations rarely come with segmented images, Max pointed out that the text could be used to guide the segmentation.
A note on inconvenient interfaces
Teaching the model to follow the user
Interactive segmentation sets itself apart from other segmentation tasks as the model needs to understand not only the images but also the users. Thus, a substantial portion of the development process is dedicated to understanding how users will want to engage with the model.
Simulating realistic interactions
Because there are only a few user-annotated segmentation datasets available, interactive segmentation models are primarily trained with simulated interactions. To ensure good deployment performance with real user interactions, it is necessary to create realistic prompts that reflect a variety of user behaviors.
However, determining how realistic scribbles look is a challenging task in itself. Medical imaging datasets with user scribbles are scarce and limited to a few task types, such as cardiac MRI segmentation. As Hallee explained, they do not encompass the real diversity of user behaviors. Moreover, Fabian noted that some scribble datasets actually contain low-quality prompts (Figure 4). For example, certain historically used segmentation methods had strong performance biases towards specific prompt properties. This has led users to adapt unnatural annotation styles to match these biases. Such scribbles may not be a good template to learn from, as they do not align with natural user behaviour.
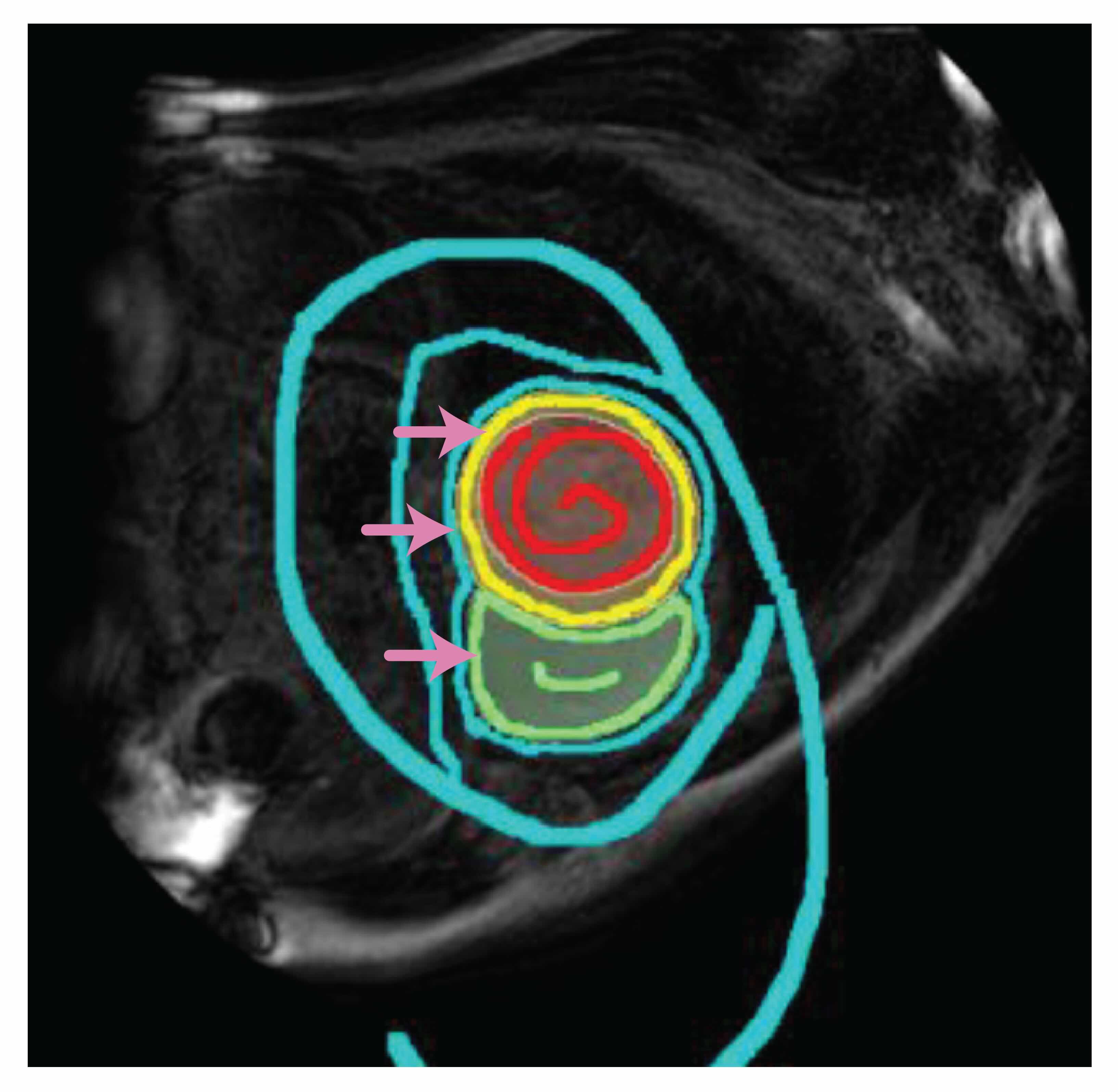 Figure 4: Example of low-quality user scribble annotation. The boundaries of the target object (middle, pink arrows) are annotated extremely precisely, not reflecting common user behaviour. The background scribbles cover only a small part of the background rather than being spread over different background regions. Target regions are annotated with red, yellow, and green scribbles, and the background with blue scribbles. The image was adapted from Figure 1 of (Li, 2023), which is under CC BY-SA 4.0 license on OpenReview.
Figure 4: Example of low-quality user scribble annotation. The boundaries of the target object (middle, pink arrows) are annotated extremely precisely, not reflecting common user behaviour. The background scribbles cover only a small part of the background rather than being spread over different background regions. Target regions are annotated with red, yellow, and green scribbles, and the background with blue scribbles. The image was adapted from Figure 1 of (Li, 2023), which is under CC BY-SA 4.0 license on OpenReview.
A new scribble dataset
In general, simulations should encompass diverse interactions, as highlighted in both ScribblePrompt and nnInteractive. This includes different stroke styles (e.g., shaky hands) as well as different levels of annotation precision and refinement steps5. Nevertheless, the interactions should not be random; they must reflect typical user behaviours. For instance, real user prompts depend on the target object. Max explained that when annotating an object with a hole, it is unlikely to draw a straight line through it with a hole in the middle. Instead, users are more likely to opt for a curved line around the hole. However, the former can occur if simulating a line that is simply trimmed in the areas outside the object mask.
Moreover, when there is no strict need for variation in prompt characteristics, it is best to keep it minimal. For example, ScribblePrompt was trained with varying scribble thicknesses and sharpness. Nevertheless, when deployed on different user interfaces, scribble blurring improved performance in some settings, as the scribbles subsequently better corresponded to the training distribution. Instead, nnInteractive used scribbles with constant line properties both during simulation and in the user interface. This simplified the model training, as it avoided the need to learn unnecessary variation.
The importance of monitoring the simulation process
Capturing diverse user intents
The primary goal of interactive models is to follow the user’s intent. Thus, strategies that steer the model into following user feedback were developed.
To generalize to new segmentation tasks, models need to be capable of segmenting any arbitrary region that the user selects. However, segmentation masks in existing datasets often exhibit bias toward specific object types. For example, numerous datasets primarily target tumour segmentation, ignoring the surrounding tissue structures. As a result, the models can memorize how to recognize the training objects and subsequently lose the ability to segment arbitrary objects.
To address this issue, strategies for increasing mask diversity were proposed. These include merging multiple masks into individual targets (e.g., combining tumor core and surrounding necrosis annotations) or creating synthetic masks with alternative segmentation approaches6. Using such diverse masks, the model can no longer memorise them and instead must learn to follow the user’s prompts.
Performance on in-distribution and out-of-distribution data
Moreover, it is important to consider which interactions the user wants the model to prioritize at each step. Usually, as users continue to refine the segmentation with additional prompts, all prior prompts are supplied to the model for the new prediction. However, the latest interaction is likely the most relevant for further improving the segmentation performance (Figure 1). Thus, past interactions are assigned decaying weights in nnInteractive.
Not all interactions are equally valuable
While it is beneficial to give users the freedom to choose different interaction methods based on their preferences, it is important to note that some types of interactions are more valuable for the model. For example, opting for a lasso or scribble instead of a bounding box does not take much more time, but it can significantly improve prediction accuracy by increasing the precision of separating target and background regions.
A note on placing the scribbles
Furthermore, it is worth considering how to schedule interactions during training. Early on, the model is not capable of producing even a rough segmentation mask, so trying to refine its output at that stage is not very useful. Instead, during early training, it is more valuable to fill each training batch with a variety of tasks (e.g., objects or image modalities), each using just a single initial prompt, rather than with multiple refinement attempts of a single poorly segmented image. As the model improves, the number of refinement steps should be gradually increased.
Managing staged training
Designing models that can run in practice
To keep latency low enough for interactive use, multiple strategies can be employed. Anwesa managed resources by minimizing the size of the model’s internal representations and operations. For example, user prompts were compressed into smaller embeddings early on, before being combined with image features (i.e., late fusion, Figure 3a). Moreover, masked attention can be employed to restrict attention operations to relevant image and prompt components (Figure 5), such as image foreground and positive prompts.
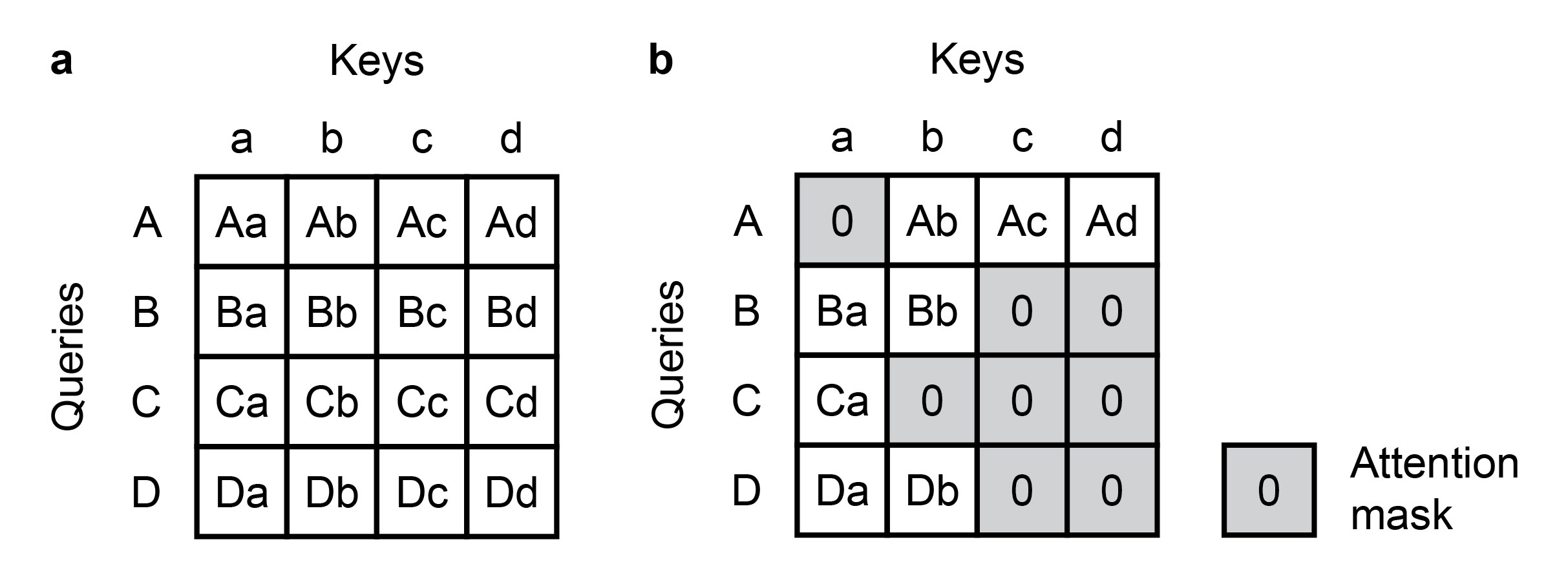 Figure 5: Masked attention (a) can be more efficient than vanilla attention (b) as the attention (key-query products) needs to be computed only for a limited set of non-masked key-query pairs. Masked key-query pairs may be directly assigned zero attention. For more information on masked attention, see Cheng (2022).
Figure 5: Masked attention (a) can be more efficient than vanilla attention (b) as the attention (key-query products) needs to be computed only for a limited set of non-masked key-query pairs. Masked key-query pairs may be directly assigned zero attention. For more information on masked attention, see Cheng (2022).
In contrast, nnInteractive feeds interactions to the model as separate image channels (i.e., early fusion), as explained above. However, this significantly increases memory use as each prompt channel matches the image size. To manage this, they keep objects on the CPU unless they are required on the GPU. For example, their AutoZoom feature starts by processing only image patches that contain the most recent prompts. The model then expands its focus to other areas only if it helps improve the segmentation.
Data loading for swifter training
Another factor that affects model efficiency during training is the preparation of the training samples. If done improperly, it can substantially slow down the training.
Large datasets and samples exceed available memory and need to be iteratively loaded from disk. As this is very time-consuming, using efficient data-loading frameworks and storage formats becomes essential (alongside other tricks7). A common solution is using NumPy’s memory-mapped array, which enables selective loading of individual segments from large files (e.g., image slices). When working in memory-mapped mode, the data stays on disk, and a connection that enables fast access to on-disk data (i.e., for reading or writing) is opened.
While NumPy’s memory-mapped arrays are a popular choice, more performant solutions are available. For example, Blosc2 allows chunked processing of compressed data. The compression not only reduces the storage size, but also the reading speed. Namely, decompressing data on modern CPUs is often quicker than reading the large uncompressed data directly from disk8. As a result, the total processing time can be lower when working with compressed rather than uncompressed files.
Furthermore, if many individual files (e.g., image samples) are present on the disk, file system access can become inefficient, resulting in longer load times. Thus, one of Halle’s colleagues developed ThunderPack - a framework that speeds up the loading of many individual samples (Figure 6). It achieves this by storing the samples in LMDB (Lightning Memory-Mapped Database) for efficient key-based disk access, where specific data (value) can be quickly retrieved based on its sample name (key). Although the database may need a few days to be built, the gains in loading speed during training make it well worth the effort.
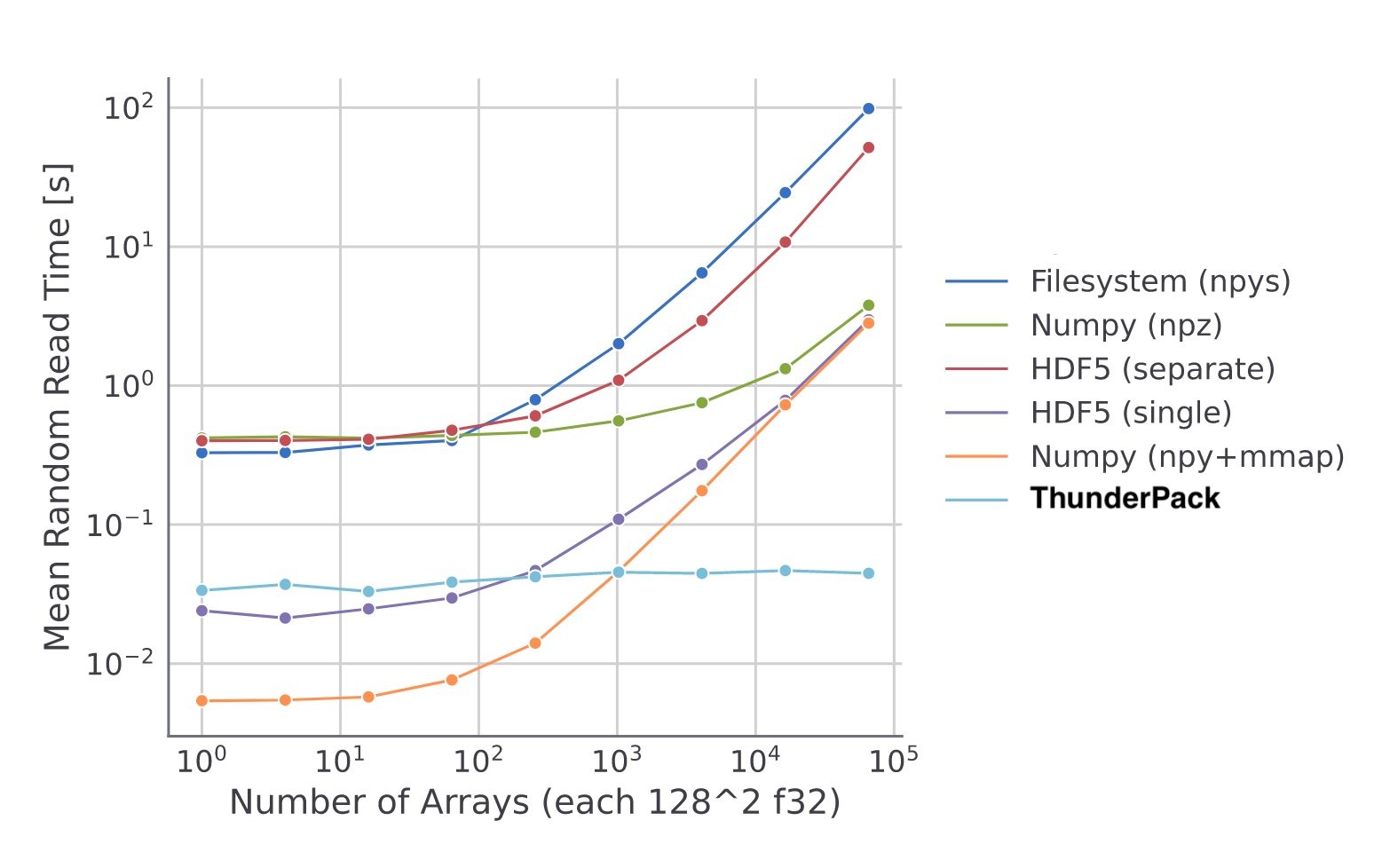 Figure 6: Time required to load arrays at random. Profiled for different total numbers of arrays. ThunderPack database outperforms other storage formats when working with many arrays. Compared to arrays stored in individual files (npys - NumPy files, HDF5 separate) or in a single array collection (npz - NumPy zip archive, HDF5 single, npy+mmap - NumPy memory mapped). The image was taken from ThunderPack’s repository, which is under the MIT license.
Figure 6: Time required to load arrays at random. Profiled for different total numbers of arrays. ThunderPack database outperforms other storage formats when working with many arrays. Compared to arrays stored in individual files (npys - NumPy files, HDF5 separate) or in a single array collection (npz - NumPy zip archive, HDF5 single, npy+mmap - NumPy memory mapped). The image was taken from ThunderPack’s repository, which is under the MIT license.
Another aspect that should not be overlooked is that some parts of the data may be quicker to access than others. For example, if data is stored in memory using row-major format, accessing row slices will be noticeably faster than column slices (Figure 7). Thus, when handling 3D images that require random access to slices along a specific dimension, it is worth reordering the arrays accordingly.
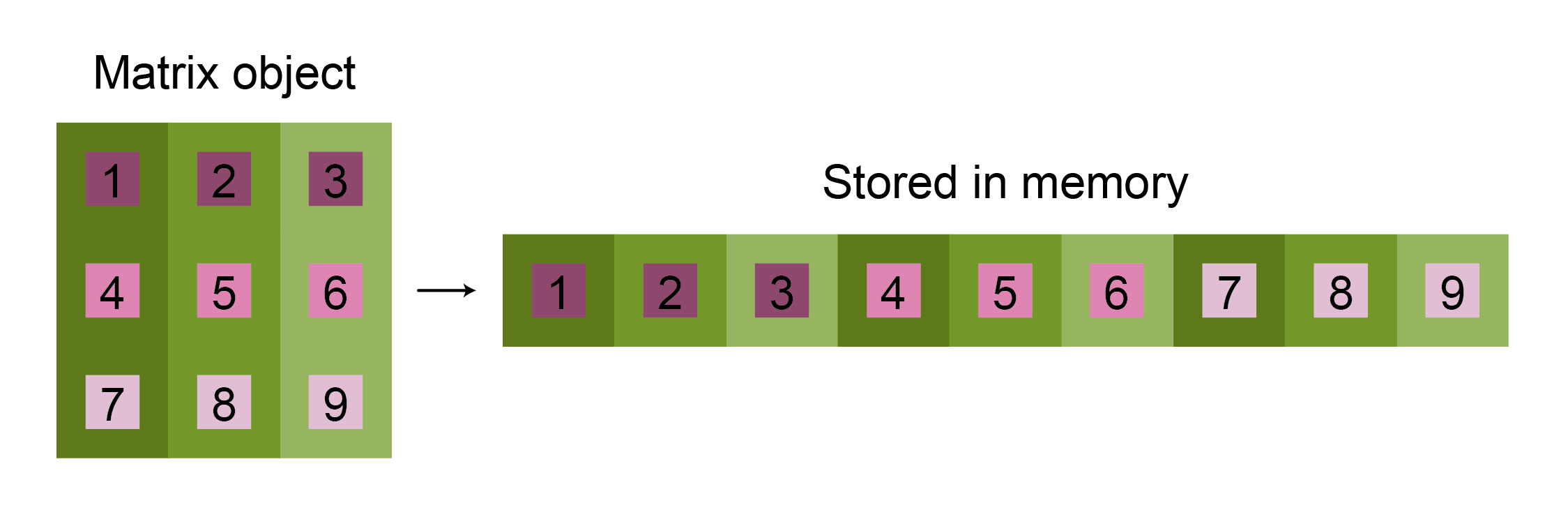 Figure 7: Matrix representation format determines the speed of accessing individual elements. Multi-dimensional arrays are commonly stored in memory as one-dimensional vectors. In the case of a row-major format, elements from one row will be stored nearby, while columns will be scattered across row chunks. As accessing nearby elements is faster, the access to elements from one row will be quicker than searching for elements belonging to a column. Converse holds for column-major ordering.
Figure 7: Matrix representation format determines the speed of accessing individual elements. Multi-dimensional arrays are commonly stored in memory as one-dimensional vectors. In the case of a row-major format, elements from one row will be stored nearby, while columns will be scattered across row chunks. As accessing nearby elements is faster, the access to elements from one row will be quicker than searching for elements belonging to a column. Converse holds for column-major ordering.
Carefully planned data curation
When considering data collection, it is easy to get caught up in contemplating over data size or diversity for training. However, Max and Hallee highlighted that defining the test data should come first, as it directly determines how the model can be used in the future. In particular, the test set should cover a wide range of tasks, including out-of-distribution cases. Afterward, the decision on what data needs to be collected for training becomes simpler9.
Data collection should be approached with an emphasis on long-term usability. Hallee pointed out that this can already pay off within the time course of an individual project, as priorities and requirements may change unexpectedly. Therefore, initial data processing should preserve as much information as possible, as explained in more detail below.
How to store data for long-term usability
- Original data, e.g., high-resolution images with all slices in 3D datasets.
- Correct alignment of all image components, including segmentation masks.
- Original metadata labels, even if new labels are added. This allows future projects to utilize a different label curation strategy.
- Tracking datasets’ origin enables appropriate citation, assess licensing constraints, and avoid the duplication of individual datasets within published data collections.
- Keeping track of who initially processed the data can help to resolve data ambiguities later on.
Data diversity for model training
While datasets are often described in terms of sample numbers, the real measure of quality lies in data diversity. Thus, before initiating training, the value of each dataset should be determined.
Fabian emphasized that this aspect is often overlooked when preparing training data. He highlighted two important factors for choosing dataset sampling probabilities during training: rarity and quality. For example, the abdomen atlas dataset contains relatively similar abdominal scans with a thousand times higher sample numbers than some rarer microscopy datasets with only a handful of images. Furthermore, during his past work, he discovered low-quality segmentation labels in some datasets. Such datasets can be challenging for models to learn from and may introduce unwanted biases, prompting him to downweight them. At the end, he also always confirms that the data distribution is appropriate by visually inspecting example training batches before proceeding with the training.
Data simulation as a future option
Key takeaways
Model building is best seen as an interactive engineering endeavour. - It calls for a deep understanding and careful optimization of individual components, going far beyond simply running grid searches over different architectures.
References
- Isensee, Rokuss, and Krämer, et al. nnInteractive: Redefining 3D Promptable Segmentation. arXiv (2025).
- Wong, et al. ScribblePrompt: Fast and Flexible Interactive Segmentation for Any Biomedical Image. ECCV (2024a).
- Wang, et al. Order-aware interactive segmentation. ICLR (2025).
- Kirillov, Mintun, Ravi, and Mao, et al. Segment anything. ICCV (2023).
- Isensee, Wald, Ulrich, and Baumgartner, et al. nnU-Net Revisited: A Call for Rigorous Validation in 3D Medical Image Segmentation. MICCAI (2024).
- Raghu and Zhang, et al. Transfusion: Understanding Transfer Learning for Medical Imaging. NeurIPS (2019).
- Wong, et al. MultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance. arXiv (2024b).
- Rokuss, et al. LesionLocator: Zero-Shot Universal Tumor Segmentation and Tracking in 3D Whole-Body Imaging. CVPR (2025).
- Isensee, et al. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods (2021).
- Billot, et al. SynthSeg: Segmentation of brain MRI scans of any contrast and resolution without retraining. Medical Image Analysis (2023).
- Li, et al. ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding. ACM MM (2023).
- Cheng, et al. Masked-attention Mask Transformer for Universal Image Segmentation. CVPR (2022).
Footnotes
The speed of the project was, besides a clear plan, also driven by the teamwork of authors with complementary expertise. Since it was clear which limitations must be overcome, each team member could effectively contribute where they were most needed. ↩︎
The project was significantly sped up by reusing existing infrastructure. The most important building block was the nnU-Net (Isensee, 2021), a self-configuring framework that they previously developed specifically for solving new medical image segmentation tasks. ↩︎
SAM is a broad-purpose interactive segmentation model for natural images. It was released in 2023 as an innovative state-of-the-art approach and has since inspired many extensions. ↩︎
Hallee noted that the SAM-based architecture was less robust against changes in image resolution. ↩︎
Ideally, the model should see different interactions before every weight update. ↩︎
Synthetic masks can be generated with non-interactive segmentation tools that segment the whole image. Alternatively, interactive tools, such as SAM, can be used with randomly placed or grid-spaced point prompts. ↩︎
Additional considerations for efficient data loading include minimizing the copying between CPU and GPU or between Python object formats (e.g., NumPy arrays and PyTorch tensors) as well as the use of loading parallelism. For example, multiple threads can be used to parallelize data loading (see this tutorial section), or different operations for transferring data from CPU to GPU can be executed simultaneously (see this tutorial). ↩︎
For more information on how Blocs2 improves data loading by better utilizing CPU resources, see this blog post. ↩︎
Collecting sufficiently diverse medical training data is especially resource-intensive, as individual datasets are very specialised, requiring curation of many data sources. ↩︎